Captive Web Portal for ESP8266 with MicroPython - Part 3
In Part 2 of this series, I finished implementing the “captive portal” DNS server so that after connecting to my Wemos D1 Mini MCU’s WiFi access point, all DNS queries pointed toward the MCU’s IP address instead of the actual IP address for the requested domain. I’m implementing this captive portal as a way to be able to configure the MCU to be able to log into my home WiFi without hardcoding the SSID and password, so what I need to do next is set up a HTTP server that will present a form where I can fill out these details.
So far, the CaptivePortal class creates the DNS Server and registers its socket with a poller that listens for data on the socket stream. This was fairly straightforward since UDP (which DNS uses) is connectionless, and I didn’t need to keep track of whether a connection was fully closed or not. I’ll do something similar for the HTTP server, but will need to keep track of which connections are incoming and outgoing, and which are closed. This makes things a little more complicated, but I’ll start with my base server class, and proceed step by step from there.
Basic HTTP server with sockets
Create a new file called captive_http.py and add the code below:
# captive_http.py
import usocket as socket
from server import Server
class HTTPServer(Server):
def __init__(self, poller, local_ip):
super().__init__(poller, 80, socket.SOCK_STREAM, "HTTP Server")
if type(local_ip) is bytes:
self.local_ip = local_ip
else:
self.local_ip = local_ip.encode()
self.request = dict()
self.conns = dict()
# queue up to 5 connection requests before refusing
self.sock.listen(5)
self.sock.setblocking(False)
def handle(self, sock, event, others):
if sock is self.sock:
# client connecting on port 80, so spawn off a new
# socket to handle this connection
print("- Accepting new HTTP connection")
self.accept(sock)
elif event & select.POLLIN:
# socket has data to read in
print("- Reading incoming HTTP data")
self.read(sock)
elif event & select.POLLOUT:
# existing connection has space to send more data
print("- Sending outgoing HTTP data")
self.write_to(sock)
Here’s the basis for how the HTTP server will look. It has a handle() method just like the DNS server did, but in this case we need to consider three different cases:
- The client wants to initiate a new request from the HTTP server. In this case the event will come in over the original “server” socket, on port 80. I’ll handle this in the
accept()method by spawning off a new “client” socket to handle that particular request/response.
Note: “client socket” in this case refers to a socket belonging to the server, but which is spawned to handle a specific client request. By contrast, the “server socket” in this discussion is only responsible for accepting new connections and creating a “client socket” for them, but doesn’t itself respond to any request.
- An existing connection (on a client socket) has sent us more data. This is signified by a
POLLINevent on the client socket, and calls theread()method to read in the data from the socket until we get to the end of the full message. - An existing connection (on a client socket) is ready for us to send more data to the client. This is signified with a
POLLOUTevent on the client socket, and I’ll handle it in thewrite_to()method by sending the next set of data for that connection.
One point to keep in mind here is that regardless of the actual size of the incoming or outgoing messages, we’ll only be sending segments of 536 bytes at a time; this is the default maximum segment size for TCP/IP.
- For reading data in from the socket, this is relatively easy: just read all data that’s sent until we get to the end. For this server, we only need to handle HTTP GET requests, so we can assume that if we find a blank line in the data (
\r\n\r\n), it is the end of the message. If we needed to handle POST requests as well, we’d need to read in theContent-LengthorTransfer-Encoding: Chunkedheaders to determine how to know when the request was finished. - For writing data out to the socket, we need to break the response up into chunks of 536 bytes each. After sending each chunk, we’ll advance a pointer to where the next chunk of data will be, then return and wait for the poller to let us know the socket is available to send more data. Once there’s no more data left to write, we close the socket.
Accepting a new socket connection
Let’s start with the easiest case: accepting a new connection. Here, we already know what socket to expect the connection request on, since it’s the same socket we created at initialization (“server socket”). The socket.accept() method will spawn off a new socket (the “client socket”) to use for this connection and return the new client socket as well as the destination address to which it’s paired.
Once I have the new client socket, I set it to non-blocking and reusable (like the server socket), and then add it to the list of open streams on which poller will listen for events.
At this point, the server socket goes back to listening for new incoming connections, and the newly-created client socket will do the work of reading in the request and writing out a response.
# captive_http.py
...
import uerrno
import uselect as select
...
class HTTPServer(Server):
...
def accept(self, server_sock):
"""accept a new client request socket and register it for polling"""
try:
client_sock, addr = server_sock.accept()
except OSError as e:
if e.args[0] == uerrno.EAGAIN:
return
client_sock.setblocking(False)
client_sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
self.poller.register(client_sock, select.POLLIN)
...
Reading from a client socket
Once we’re spawned off a client socket for an incoming connection request, and set it up for polling, we should expect a subsequent POLLIN event (or several) where the client is sending us data that we need to read in. The way we’re building this project, we can assume that any POLLIN event that doesn’t belong to the DNS socket is going to be a client socket for the HTTP server, so we can just pass them all to our new read() method below.
Calling the incoming socket’s read() method gives us some amount of data, but we don’t know upfront whether it’s the full message or a partial message. If there’s no data, it’s a good sign that we already hit the end of the message, and we should just close the socket now.
Otherwise, let’s check if we’re already partway through an incoming message for this client socket. If we are, add the new data to the existing partial message, otherwise create an empty bytestring and append the data.
Here, we’re going to cheat a little bit since we only need to handle GET requests, and we can assume that any blank line signifies the end of the message. If the last four bytes of the incoming data is not \r\n\r\n, we expect there’s more to come, so return early and wait for the next POLLIN event.
If we did find a blank line at the end, get the full request and print it out so we can take a look. The client will be expecting a message back, so for now let’s just queue up a 404 Not Found message to get them off our backs until we can code up a way to send real HTML.
# captive_http.py
...
import uio
...
class HTTPServer(Server):
...
def read(self, s):
"""read in client request from socket"""
data = s.read()
if not data:
# no data in the TCP stream, so close the socket
self.close(s)
return
# add new data to the full request
sid = id(s)
self.request[sid] = self.request.get(sid, b"") + data
# check if additional data expected
if data[-4:] != b"\r\n\r\n":
# HTTP request is not finished if no blank line at the end
# wait for next read event on this socket instead
return
# get the completed request
req = self.request.pop(sid)
print("Client raw request:\n", req)
# send a 404 response for now
headers = b"HTTP/1.1 404 Not Found\r\n"
body = uio.BytesIO(b"")
self.prepare_write(s, body, headers)
...
Sending to a client socket
Now all that’s left to complete the HTTP transaction is to write a response back to the client. Remember that we’re limited to writing 536 bytes at a time, but our response may be longer than that. In the previous section, after reading in the request, we called prepare_write() with the headers and body we wanted to send back to the client. We’ll need a way to keep track of how much data we’ve written out for each response, and where we should start writing next time the same socket is ready to accept more of our response.
To help keep track of all that, I made a namedtuple for the writer connection that contains:
- The full response body we need to send
- A buffer that will contain only the next 536 (maximum) bytes we plan to send
- A memoryview of the buffer to help with writing in and out of the buffer without needless copying
- A range for starting and ending bytes of the buffer that we want to send next.
Notice that I’m not keeping a copy of the headers, since they’ll always (in our case) be less than 536 bytes and will always go out with the first message segment.
With all that in place, I’m adding an extra newline to the headers to get a blank line (required between headers and body), and then writing the headers into the buffer (padded to make the buffer size 536 bytes). Then I use the memoryview to read from the body into the buffer, up to a maximum total of 536 bytes in the buffer. The readinto() call tells me how many bytes were actually read from body into the buffer, and I use that number to set the end point of the write_range. I save the WriteConn information into the self.conns dictionary with a key of the socket’s ID so I can look it up later when I need to write the remainder of the message.
Lastly, I let the poller know that I’m prepared to write out to the socket, so it can let me know when the socket is available for outgoing data. This means I’ll start getting POLLOUT events for this socket, which I’ll need to handle to actually start writing this data.
# captive_http.py
...
from collections import namedtuple
WriteConn = namedtuple("WriteConn", ["body", "buff", "buffmv", "write_range"])
...
class HTTPServer(Server):
...
def prepare_write(self, s, body, headers):
# add newline to headers to signify transition to body
headers += "\r\n"
# TCP/IP MSS is 536 bytes, so create buffer of this size and
# initially populate with header data
buff = bytearray(headers + "\x00" * (536 - len(headers)))
# use memoryview to read directly into the buffer without copying
buffmv = memoryview(buff)
# start reading body data into the memoryview starting after
# the headers, and writing at most the remaining space of the buffer
# return the number of bytes written into the memoryview from the body
bw = body.readinto(buffmv[len(headers) :], 536 - len(headers))
# save place for next write event
c = WriteConn(body, buff, buffmv, [0, len(headers) + bw])
self.conns[id(s)] = c
# let the poller know we want to know when it's OK to write
self.poller.modify(s, select.POLLOUT)
...
Now that the poller is set to pass POLLOUT events to this client socket, we need to handle those events, which will trigger a call to our new write_to() method. First, we need to get the writer connection back, which will have everything we need to determine which bytes should be written out. Remember that the write_range value of this tuple is a list of start and end positions of the buffer that we should write:
- If the buffer is full, this would normally be
[0, 536], and we’d write the entire contents of the buffer. - If the buffer is only partially full, the second value in the list would be something less than 536.
- If we got interrupted while writing last time, the first value may be something higher than 0, and we’e start writing from that position instead of 0.
After writing out to the socket, we check how much was written. If we didn’t write any bytes, or we had less than 536 bytes to write, we’re done sending this response, and we can close the socket.
Otherwise, we wrote all the bytes in the buffer, so we need to keep the socket open, advance the buffer to the next bytes of the response body so that when the next POLLOUT event comes in, we’ll be prepared to continue writing; this part happens in the buff_advance() method.
# captive_http.py
...
class HTTPServer(Server):
...
def write_to(self, sock):
"""write the next message to an open socket"""
# get the data that needs to be written to this socket
c = self.conns[id(sock)]
if c:
# write next 536 bytes (max) into the socket
bytes_written = sock.write(
c.buffmv[c.write_range[0] : c.write_range[1]]
)
if not bytes_written or c.write_range[1] < 536:
# either we wrote no bytes, or we wrote < TCP MSS of bytes
# so we're done with this connection
self.close(sock)
else:
# more to write, so read the next portion of the data into
# the memoryview for the next send event
self.buff_advance(c, bytes_written)
def buff_advance(self, c, bytes_written):
"""advance the writer buffer for this connection to next outgoing bytes"""
if bytes_written == c.write_range[1] - c.write_range[0]:
# wrote all the bytes we had buffered into the memoryview
# set next write start on the memoryview to the beginning
c.write_range[0] = 0
# set next write end on the memoryview to length of bytes
# read in from remainder of the body, up to TCP MSS
c.write_range[1] = c.body.readinto(c.buff, 536)
else:
# didn't read in all the bytes that were in the memoryview
# so just set next write start to where we ended the write
c.write_range[0] += bytes_written
...
Closing a client socket
There were a few cases above where we needed to close a client socket, either because we were done writing to it, or else done reading from it. Note that we never close the server socket (until we stop our program), since we want to be able to continue listening for incoming connection requests.
To cleanly close a client socket, we also need to unregister it from the poller, and delete any remaining request or connection data we had stored for it. Since we have very limited RAM on the ESP8266, we do this manually and then call the garbage collector to make sure we’re conserving every single byte of RAM as early as possible to avoid memory errors.
# captive_http.py
...
import gc
...
class HTTPServer(Server):
...
def close(self, s):
"""close the socket, unregister from poller, and delete connection"""
s.close()
self.poller.unregister(s)
sid = id(s)
if sid in self.request:
del self.request[sid]
if sid in self.conns:
del self.conns[sid]
gc.collect()
...
Adding the HTTP server to our CaptivePortal class
Now that we have the skeleton of the HTTP server set up, let’s instantiate one in the CaptivePortal class and add it to the polling loop. We can test that we’re actually reading in data correctly before we move on to actually correctly handling requests.
We previously wrote our handle_dns() method so that it returned False if it didn’t handle the stream event, and True if it did. We’ll make use of this here to make sure the HTTP server doesn’t try to handle events that don’t belong to it or one of its child client sockets.
# captive_portal.py
...
from captive_dns import DNSServer
from captive_http import HTTPServer
class CaptivePortal:
...
def __init__(self, essid=None):
...
self.dns_server = None
self.http_server = None
...
def captive_portal(self):
print("Starting captive portal")
self.start_access_point()
if self.http_server is None:
self.http_server = HTTPServer(self.poller, self.local_ip)
print("Configured HTTP server")
if self.dns_server is None:
self.dns_server = DNSServer(self.poller, self.local_ip)
print("Configured DNS server")
try:
while True:
gc.collect()
# check for socket events and handle them
for response in self.poller.ipoll(1000):
sock, event, *others = response
is_handled = self.handle_dns(sock, event, others)
if not is_handled:
self.handle_http(sock, event, others)
except KeyboardInterrupt:
print("Captive portal stopped")
self.cleanup()
def handle_http(self, sock, event, others):
self.http_server.handle(sock, event, others)
...
Time to test it out. Copy the code to the MCU and start it up. Connect to the MCU’s access point with your phone, and then open a browser and try to navigate to a non-HTTPS page (http://neverssl.com, http://example.com, for example).
Entering REPL. Use Control-X to exit.
>
MicroPython v1.12 on 2019-12-20; ESP module with ESP8266
Type "help()" for more information.
>>>
>>> import main
Trying to load WiFi credentials from ./wifi.creds
./wifi.creds does not exist
Starting captive portal
Waiting for access point to turn on
#37 ets_task(4020f510, 29, 3fff8f88, 10)
AP mode configured: ('192.168.4.1', '255.255.255.0', '192.168.4.1', '192.168.4.1')
HTTP Server listening on ('0.0.0.0', 80)
Configured HTTP server
DNS Server listening on ('0.0.0.0', 53)
Configured DNS server
Sending connectivitycheck.gstatic.com. -> 192.168.4.1
- Accepting new HTTP connection
- Reading incoming HTTP data
Client raw request:
b'GET /generate_204 HTTP/1.1\r\nUser-Agent: Dalvik/2.1.0 (Linux; U; Android 6.0.1;
Nexus 7 Build/MOB30X)\r\nHost: connectivitycheck.gstatic.com\r\nConnection:
Keep-Alive\r\nAccept-Encoding: gzip\r\n\r\n'
- Sending outgoing HTTP data
Captive portal stopped
Cleaning up
DNS Server stopped
This looks good. We can see that the DNS server is redirecting all domains to the MCU’s IP address, and then the HTTP server is accepting the connection and reading in the request data. This particular request is my Android device checking whether it has active internet or not. iOS devices do something similar, but with a different endpoint. If you wanted to trick the device into thinking it actually had an internet connection, all you’d need to do is respond to this request with a 204 No Content response. If you’re curious how this works, this article has some additional detail.
Setting up routes and serving actual responses
So far, we’re responding to all requests with a 404 Not Found header and an empty body. Obviously we’re going to need to send real responses to make this work. There’s two things we need to get started with this:
- Some actual content in the form of HTML files.
- A way to examine the request, get the path requested, and map that to a specific HTML file.
Captive portal landing HTML page
Since the goal of this project is to let me enter my home WiFi credentials so the MCU can connect to it, I’ll need a simple HTML page with a form on it where I can enter those details. I created a file called index.html with a basic form and a bit of inline styling. Since this is an extremely simple page on a very basic server, I’m OK with using inline CSS instead of a separate file to make serving things simpler for me.
<!-- index.html -->
<html>
<head>
<meta charset="utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<title>WiFi Login</title>
<style>
body {
font-family: sans-serif;
background: #3498db;
width: 100%;
text-align: center;
margin: 20px 0px 20px 0px;
}
p {
font-size: 12px;
text-decoration: none;
color: #fff;
}
h1 {
font-size: 1.5em;
color: #525252;
}
.box {
background: white;
width: 50%;
border-radius: 6px;
margin: 0 auto 0 auto;
padding: 10px 0px 10px 0px;
}
input[type='text'],
input[type='password'] {
background: #ecf0f1;
border: #ccc 1px solid;
border-bottom: #ccc 2px solid;
padding: 8px;
width: 60%;
color: #aaa;
margin-top: 10px;
font-size: 1em;
border-radius: 4px;
}
.btn {
background: #2ecc71;
width: 40ch;
padding-top: 5px;
padding-bottom: 5px;
color: white;
border-radius: 4px;
border: #27ae60 1px solid;
margin: 20 auto;
font-weight: 800;
font-size: 0.8em;
}
</style>
</head>
<body>
<form action="/login" method="get" class="box">
<h1>WiFi login credentials</h1>
<input type="text" placeholder="My WiFi SSID" name="ssid" required />
<br />
<input
type="password"
placeholder="WiFi Password"
name="password"
required
/>
<br />
<button type="submit" class="btn">Connect</button>
</form>
</body>
</html>
Mapping files to HTTP paths
Now that I have a HTML file, I need to tell my server which HTTP paths should serve that file. Let’s add a routes dictionary to the HTTPServer class. If I was making a more general-purpose HTTP server, I’d probably want to create a method for adding routes, and let the parent create the routes instead of having the server do it directly. In this case, however, I’ll have a very limited number of routes that will never change, so I’m just going to create them through a dictionary literal in the HTTPServer constructor.
# captive_http.py
...
class HTTPServer(Server):
def __init__(self, poller, local_ip):
...
self.request = dict()
self.conns = dict()
self.routes = {b"/": b"./index.html"}
...
HTTP routing based on requested path
Now that we have a file created, and know what route should serve that file, we just need to examine each incoming request to see what path is being requested, and respond appropriately.
First, let’s parse the HTTP request and pull out the details we may be interested in:
# captive_http.py
...
ReqInfo = namedtuple("ReqInfo", ["type", "path", "params", "host"])
...
class HTTPServer(Server):
...
def parse_request(self, req):
"""parse a raw HTTP request to get items of interest"""
req_lines = req.split(b"\r\n")
req_type, full_path, http_ver = req_lines[0].split(b" ")
path = full_path.split(b"?")
base_path = path[0]
query = path[1] if len(path) > 1 else None
query_params = (
{
key: val
for key, val in [param.split(b"=") for param in query.split(b"&")]
}
if query
else {}
)
host = [line.split(b": ")[1] for line in req_lines if b"Host:" in line][0]
return ReqInfo(req_type, base_path, query_params, host)
def read(self, s):
...
# get the completed request
req = self.parse_request(self.request.pop(sid))
# send a 404 response for now
headers = b"HTTP/1.1 404 Not Found\r\n"
body = uio.BytesIO(b"")
self.prepare_write(s, body, headers)
...
Then, I’ll create a helper function to take the parsed request and either return either the contents of the HTML file if the route matches, or else an empty byte string. Add the following to captive_html.py:
# captive_http.py
...
class HTTPServer(Server):
...
def get_response(self, req):
"""generate a response body and headers, given a route"""
headers = b"HTTP/1.1 200 OK\r\n"
route = self.routes.get(req.path, None)
if type(route) is bytes:
# expect a filename, so return contents of file
return open(route, "rb"), headers
headers = b"HTTP/1.1 404 Not Found\r\n"
return uio.BytesIO(b""), headers
...
If the route is found, I’ll get a bytes string with the path to the HTML file, and I’ll open that file (in binary mode) and return the file stream object.
If the route is not found, I’ll get a None from the dictionary, and instead I’ll return an empty bytes stream object. In both cases, I’ll return appropriate headers along with the body.
Let’s modify the read() function to try to get a body depending on the route, and also generate a correct header depending on whether the route was matched or not:
# captive_http.py
...
class HTTPServer(Server):
...
def read(self, s):
...
# get the completed request
req = self.parse_request(self.request.pop(sid))
body, headers = self.get_response(req)
self.prepare_write(s, body, headers)
...
Time to test it out. Copy all the new/changed files over to the MCU, and fire it up.
Note: don’t forget to copy your new
index.htmlfile onto the MCU as well, along with the.pyfiles. Place the HTML files in the same folder (/pyboard) as the others.
Once the captive portal is running, connect to the MCU’s WiFi access point and navigate to http://192.168.4.1/
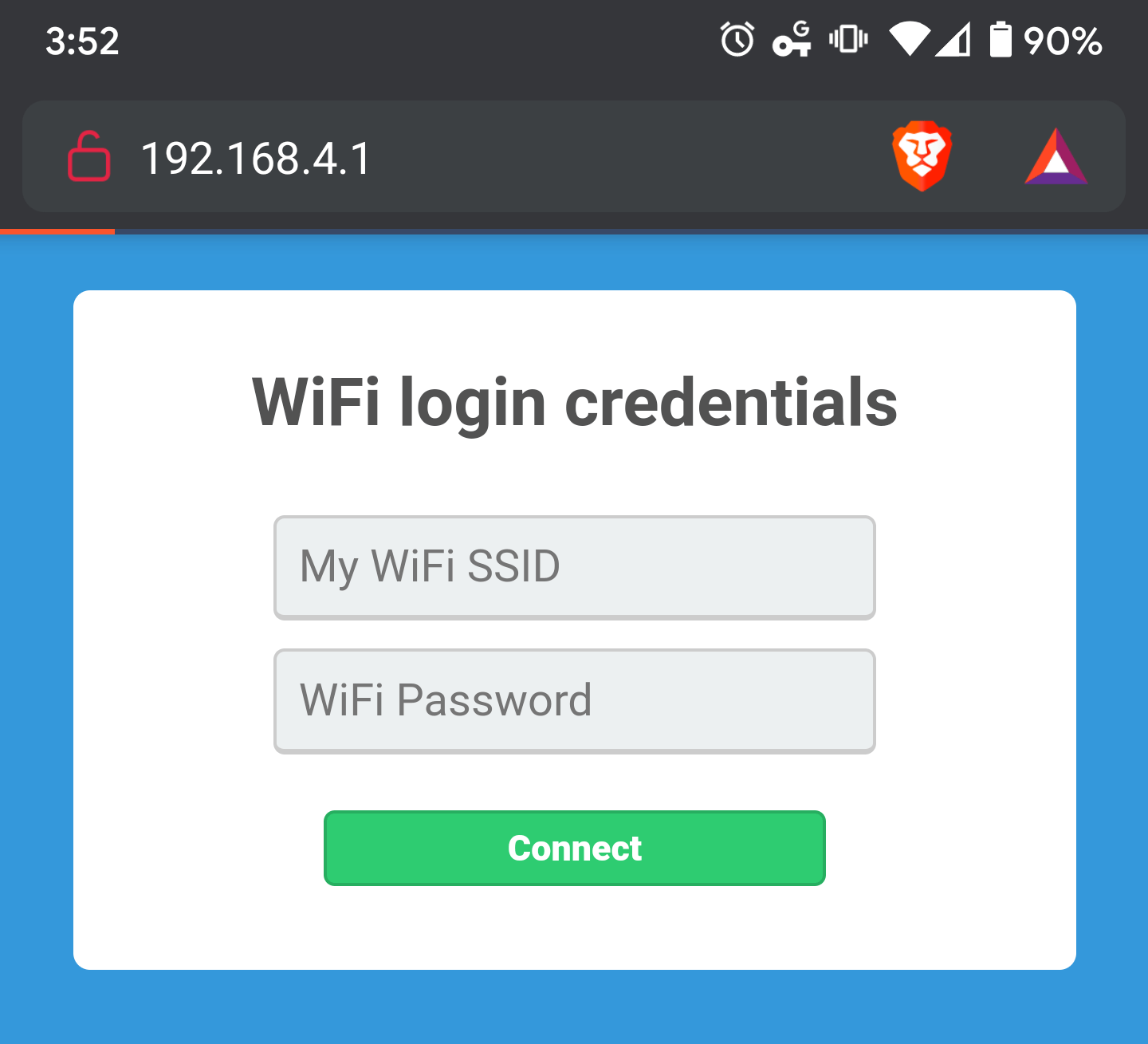
Captive portal login page
Actually, if you navigate to any HTTP-only site, at the root path, you’ll get the same page since our DNS server is telling the client that all domains point to the MCU’s IP address. You can test this by navigating to any site that doesn’t use HTTPS (try http://neverssl.com to test). This is definitely progress, but still not quite what we want. If (for example), I tried navigating to http://neverssl.com/online, I’d get a 404 Not Found back from the server instead of it redirecting me to the login page I want. Additionally, it kind of bugs me that the domain I tried navigating to still shows up in the browser address bar instead of the MCU’s IP address.
Redirecting to the captive portal
Both of these issues can be basically solved in the same way: if the requested host or path from the client are not the ones I want to serve, I can send a redirect response back to the client to point them where I want them to go. This response will just be an empty body with a 307 Temporary Redirect header.
Let’s modify the HTTPServer.read() method to check for a valid request. If the requested host matches the MCU’s IP address, and the route is known, then serve the page for that route. Otherwise, return a redirect response pointing to the root path of the MCU’s IP address.
# captive_http.py
...
class HTTPServer(Server):
...
def read(self, s):
...
# get the completed request
req = self.parse_request(self.request.pop(sid))
if not self.is_valid_req(req):
headers = (
b"HTTP/1.1 307 Temporary Redirect\r\n"
b"Location: http://{:s}/\r\n".format(self.local_ip)
)
body = uio.BytesIO(b"")
self.prepare_write(s, body, headers)
return
# by this point, we know the request has the correct
# host and a valid route
body, headers = self.get_response(req)
self.prepare_write(s, body, headers)
...
Then we can write the is_valid_req() method like this:
# captive_http.py
...
class HTTPServer(Server):
...
def is_valid_req(self, req):
if req.host != self.local_ip:
# force a redirect to the MCU's IP address
return False
# redirect if we don't have a route for the requested path
return req.path in self.routes
...
Go ahead and test that out. Any non-HTTPS domain you try, with any path, should redirect you back to http://192.168.4.1, which matches the route for the index page with the login form.
Recap
We’ve made progress, but still don’t have a functioning product yet. The D1 Mini has a working DNS server to point all domain requests to the local IP address, and a HTTP server that will redirect all unknown hosts and paths to the root path of the local IP address, which will now serve a form asking for the WiFI SSID and password where we want the D1 Mini to connect in the future.
All that’s left is to actually parse the form submission, have the D1 Mini try to connect to the new WiFi, and then let the user know if it was successful. This is stretching into a longer writeup than I was anticipating, but I didn’t want to skimp too much on the details, or make any post too long to comfortably follow.
Next: Captive Web Portal for ESP8266 with MicroPython - Part 4
Code: GitHub project repo
Found a problem with this post? Submit a PR to fix it here: GitHub website repo